Go 语言并发学习-协程 goroutine
创建 \ 退出 goroutine
只需要通过 go 关键字来开启 goroutine 即可。
go 函数名( 参数列表 )
如下所示:
package main
import (
"fmt"
"time"
)
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println(s)
}
}
func main() {
go say("world")
say("hello")
}
当 main() 函数返回的时候该 goroutine 就结束了,所有在 main() 函数中启动的 goroutine 会一同结束
但是非 main() 函数中的主协程退出了,其他任务还会执行
退出协程使用 runtime.Goexit()
import (
"fmt"
"runtime"
)
func main() {
go func() {
defer fmt.Println("A.defer")
// 执行一个匿名函数
func() {
defer fmt.Println("B.defer")
// 结束协程
runtime.Goexit()
defer fmt.Println("C.defer") // 不执行
fmt.Println("B") // 不执行
}()
fmt.Println("A") // 不执行
}()
for {
}
}
打印结果为
B.defer
A.defer
// 因为下面 for 是死循环,所以手动结束进程
协程的状态
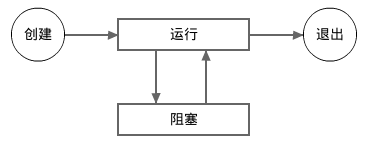
注意,一个处于睡眠中的(通过调用 time.Sleep)或者在等待系统调用返回的协程被认为是处于运行状态,而不是阻塞状态。
当一个新协程被创建的时候,它将自动进入运行状态,一个协程只能从运行状态而不能从阻塞状态退出。 如果因为某种原因而导致某个协程一直处于阻塞状态,则此协程将永远不会退出。 除了极个别的应用场景,在编程时我们应该尽量避免出现这样的情形。
一个处于阻塞状态的协程不会自发结束阻塞状态,它必须被另外一个协程通过某种并发同步方法来被动地结束阻塞状态。 如果一个运行中的程序当前所有的协程都出于阻塞状态,则这些协程将永远阻塞下去,程序将被视为死锁了。
当一个程序死锁后,官方标准编译器的处理是让这个程序崩溃。
比如下面这个程序将在运行两秒钟后崩溃。
package main
import (
"sync"
"time"
)
var wg sync.WaitGroup
func main() {
wg.Add(1)
go func() {
time.Sleep(time.Second * 2)
wg.Wait() // 阻塞在此
}()
wg.Wait() // 阻塞在此
}
它的输出:
fatal error: all goroutines are asleep - deadlock!
...
下面这张图显示了一个协程的更详细的生命周期。在此图中,运行状态被细分成了多个子状态。 一个处于排队子状态的协程等待着进入执行子状态。一个处于执行子状态的协程在被执行一会儿(非常短的时间片)之后将进入排队子状态。
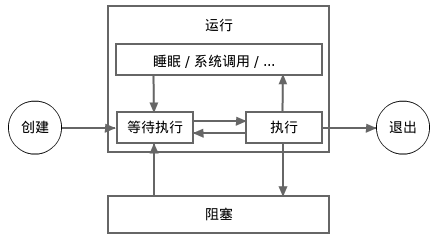
重申一下,睡眠和等待系统调用返回子状态被认为是运行状态,而不是阻塞状态。
超时返回时的陷阱
超时控制在网络编程中是非常常见的,利用 context.WithTimeout 和 time.After 都能够很轻易地实现。
time.After 实现超时控制
func doBadthing(done chan bool) {
time.Sleep(time.Second)
done <- true
}
func timeout(f func(chan bool)) error {
done := make(chan bool)
go f(done)
select {
case <-done:
fmt.Println("done")
return nil
case <-time.After(time.Millisecond):
return fmt.Errorf("timeout")
}
}
// 调用这个超时方法
timeout(doBadthing)
上述代码是一个典型的实现超时的例子。
- 利用
time.After启动了一个异步的定时器,返回一个 channel,当超过指定的时间后,该 channel 将会接受到信号。 - 启动了子协程执行函数 f,函数执行结束后,将向 channel done 发送结束信号。
- 使用 select 阻塞等待 done 或
time.After的信息,若超时,则返回错误,若没有超时,则返回 nil。
如果每次调用,函数 f 都能够在超时前正常结束,那么启动的子协程(goroutine)能够正常退出。那如果是超时场景呢?子协程能够正常退出么?
测试协程是否退出
在这个例子中超时时间为 1 ms,而 doBadthing 需要 1s 才能结束运行。因此 timeout(doBadthing) 一定会触发超时。我们利用单元测试,来看一看超时场景下协程的情况。
func test(t *testing.T, f func(chan bool)) {
t.Helper() // Helper 将调用该函数的标记为测试 Helper 函数
for i := 0; i < 1000; i++ {
timeout(f)
}
time.Sleep(time.Second * 2)
t.Log(runtime.NumGoroutine()) // 打印协程个数
}
func doBadthing(done chan bool) {
time.Sleep(time.Second)
done <- true
}
func TestBadTimeout(t *testing.T) { test(t, doBadthing) }
timeout(doBadthing)调用了 1000 次,理论上会启动 1000 个子协程。- 利用
runtime.NumGoroutine()打印当前程序的协程个数。 - 因为 doBadthing 执行时间为 1s,因此打印协程个数前,等待 2s,确保函数执行完毕。
测试结果如下:
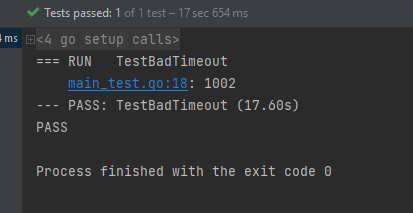
最终程序中存在着 1002 个子协程,说明即使是函数执行完成,协程也没有正常退出。那如果在实际的业务中,我们使用了上述的代码,那越来越多的协程会残留在程序中,最终会导致内存耗尽(每个协程约占 2K 空间),程序崩溃。
我们仔细阅读这段代码,其实是非常容易发现问题所在的。
done 是一个无缓冲区的 channel,如果没有超时,doBadthing 中会向 done 发送信号,select 中会接收 done 的信号,因此 doBadthing 能够正常退出,子协程也能够正常退出。
但是,当超时发生时,select 接收到 time.After 的超时信号就返回了,done 没有了接收方(receiver),而 doBadthing 在执行 1s 后向 done 发送信号,由于没有接收者且无缓存区,发送者(sender)会一直阻塞,导致协程不能退出。
如何避免呢?主要有以下方法:
1.创建有缓冲区的 channel
即创建 channel done 时,缓冲区设置为 1,即使没有接收方,发送方也不会发生阻塞。(这里默认是 0)
对于非缓存通道:无论发送操作还是接受操作一开始就是阻塞的,只有配对的操作出现才会开始执行。所以当接收方或者发送方一方没了都会造成阻塞
更改后
func timeoutWithBuffer(f func(chan bool)) error {
done := make(chan bool, 1)
go f(done)
select {
case <-done:
fmt.Println("done")
return nil
case <-time.After(time.Millisecond):
return fmt.Errorf("timeout")
}
}
func TestBufferTimeout(t *testing.T) {
for i := 0; i < 1000; i++ {
timeoutWithBuffer(doBadthing)
}
time.Sleep(time.Second * 2)
t.Log(runtime.NumGoroutine())
}
func doBadthing(done chan bool) {
time.Sleep(time.Second)
done <- true
}
测试结果如下:
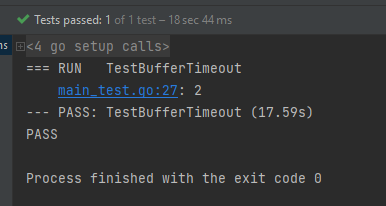
协程数量下降为 2,创建的 1000 个子协程成功退出。
2.使用 select 尝试发送
设置缓冲区是一种方式,还有另一种方式:
func doGoodthing(done chan bool) {
time.Sleep(time.Second)
select {
case done <- true:
default:
return
}
}
func TestGoodTimeout(t *testing.T) { test(t, doGoodthing) }
使用 select 尝试向信道 done 发送信号,如果发送失败,则说明缺少接收者(receiver),即超时了,那么直接退出即可。
多段超时任务终止
还有一些更复杂的场景,例如将任务拆分为多段,只检测第一段是否超时,若没有超时,后续任务继续执行,超时则终止。
func do2phases(phase1, done chan bool) {
time.Sleep(time.Second) // 第 1 段
select {
case phase1 <- true:
default:
return
}
time.Sleep(time.Second) // 第 2 段
done <- true
}
func timeoutFirstPhase() error {
phase1 := make(chan bool)
done := make(chan bool)
go do2phases(phase1, done)
select {
case <-phase1:
<-done
fmt.Println("done")
return nil
case <-time.After(time.Millisecond):
return fmt.Errorf("timeout")
}
}
func Test2phasesTimeout(t *testing.T) {
for i := 0; i < 1000; i++ {
timeoutFirstPhase()
}
time.Sleep(time.Second * 3)
t.Log(runtime.NumGoroutine())
}
这种场景在实际的业务中更为常见,例如我们将服务端接收请求后的任务拆分为 2 段,一段是执行任务,一段是发送结果。那么就会有两种情况:
- 任务正常执行,向客户端返回执行结果。
- 任务超时执行,向客户端返回超时。
这种情况下,就只能够使用 select,而不能能够设置缓冲区的方式了。因为如果给信道 phase1 设置了缓冲区,phase1 <- true 总能执行成功,那么无论是否超时,都会执行到第二阶段,而没有即时返回,这是我们不愿意看到的。对应到上面的业务,就可能发生一种异常情况,向客户端发送了 2 次响应:
- 任务超时执行,向客户端返回超时,一段时间后,向客户端返回执行结果。
缓冲区不能够区分是否超时了,但是 select 可以(没有接收方,信道发送信号失败,则说明超时了)。
有栈协程和无栈协程
有栈协程和无栈协程是根据它们存储上下文的机制区分命名的
有栈协程就是实现了一个用户态的线程,用户可以在堆上模拟出协程的栈空间,当需要进行协程上下文切换的时候,主线程只需要交换栈空间和恢复协程的一些相关的寄存器的状态就可以实现一个用户态的线程上下文切换,没有了从用户态转换到内核态的切换成本,协程的执行也就更加高效。
而一般无栈协程是使用 状态机模拟线程,执行完了一个状态后挂起,等待执行下一个状态 的行为进行优化调度(也有靠迭代器的,例如 Unity)。因为无栈协程还是共享同一个系统栈,所以无法做到在其任意嵌套函数中被挂起
比如使用无栈协程的 JavaScript 就不能这么写:
async function processArray(array) {
// 显然这里 forEach 是个嵌套函数(未用 async 修饰)
array.forEach(item => {
// Uncaught SyntaxError:
// await is only valid in async function
const result = await processItem(item)
...
})
}
但使用有栈协程的 Golang 就可以轻松实现类似的逻辑:
func processArray(array []int) {
for i := 0; i < len(array); i++ {
ch := make(chan int)
go processItem(array[i], ch)
result := <- ch
...
}
}
TODO: 学习了,kotlin 的协程实现 CPS 再更新...